Guide for the API¶
(updated 2025-07-15 using v0.16.1)
Introduction¶
The Application Programming Interface (API) is a core feature of the OpenStudyBuilder, as integrations with other tools are key to enable fully automated processes and a single source of truth. The heart of the MDR is the graph database which is a Neo4j database. One possible approach to communicating with a database is querying it directly, but APIs allow for controlled operations. This can be used to enforce business logic and domain-oriented views of data. But APIs allow for more controlled operations on the database by enforcing the business logic and providing a more domain-oriented view on the data. The OpenStudyBuilder web application displays all its contents by requesting this information from the database via the API.
The OpenStudyBuilder API allows you for example to:
- GET a list of all studies
- GET information of one study
- PATCH information for one study
- GET a list of all ODM templates (CRF templates)
- GET a list of all ODM forms
- Receive an ODM XML for a given template
API Definition¶
Quote
An application programming interface (API) is a way for two or more computer programs to communicate with each other. It is a type of software interface, offering a service to other pieces of software. A document or standard that describes how to build or use such a connection or interface is called an API specification.[1]
[1] Wikipedia entry for API, https://en.wikipedia.org/wiki/API
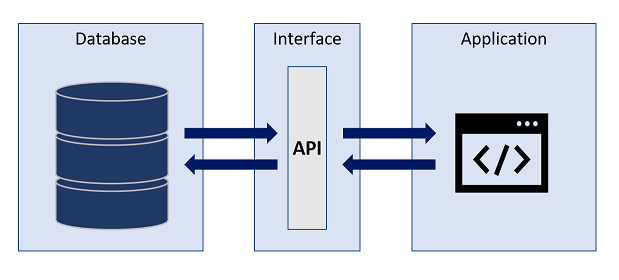
Figure 1: Simplified API process
OpenStudyBuilder API Design¶
The OpenStudyBuilder architeture is utilizing the API for dedicted connections. APIs are not only available for the OpenStudyBuilder, but are utilized by many other tools as these make the communication between systems much easier.
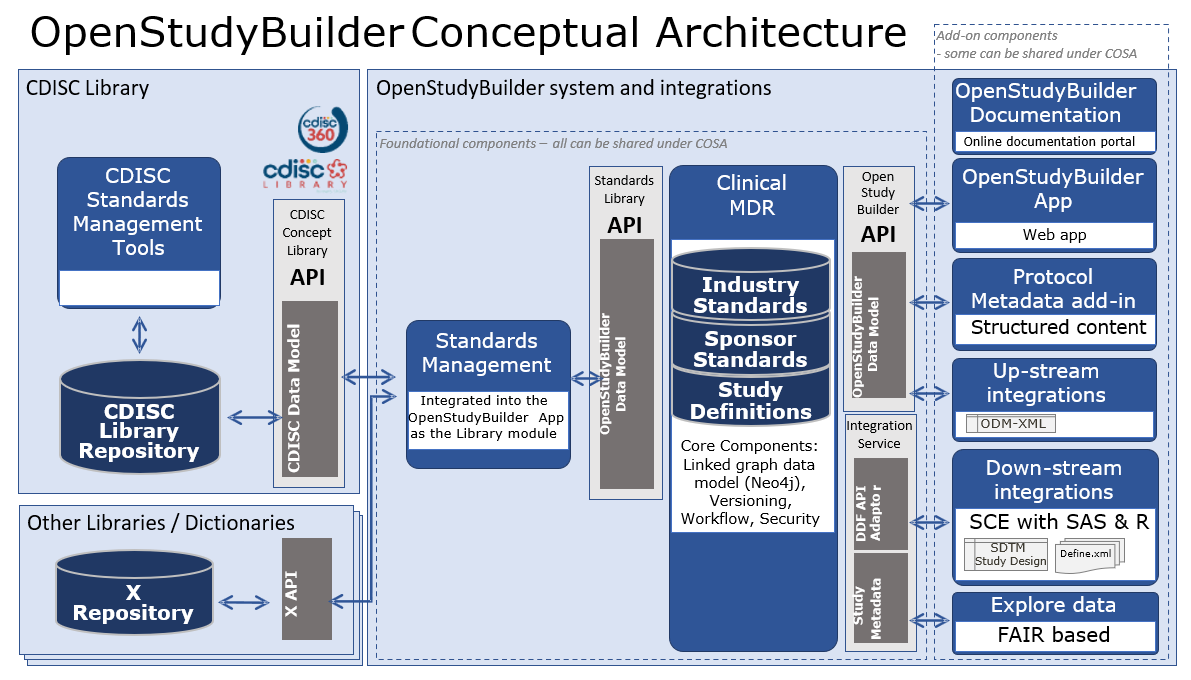
Figure 2: OpenStudyBuilder Conceptual Architecture
Let us start on the left side. The CDISC Library expose its data through an API, so this can be used by a program to load relevant data. Other library and dictionary providers might have an API where the data can be loaded from one system to another automatically. For the OpenStudyBuilder we have standard import programs in place which read the data from the CDISC API and stores the data in the database using the OpenStudyBuilder API - there are many parts in the API just responsible for standard imports.
On the right side is the OpenStudyBuilder application which is also only communicating with the database through the OpenStudyBuilder API. Other tools like a protocol tool (not open-sourced currently) also access the data needed for their use-cases through the API. Addition use-cases could be, but not limited to, EDC tools which use the API to import and export ODM-XML metadata updates.
The OpenStudyBuilder API is very powerful and contains a lot of endpoints to work with the data. Tool integrations are typically very difficult, but will be easier by utilizing APIs. To integrate multiple systems is still challenging, as every tool is using different interfaces. To overcome integration issues, the TransCelerate DDF project is working together with CDISC on API standards. The OpenStudyBuilder has an DDF-API Endpoint available which can be used (see DDF-API Overview). This enables any software supporting the DDF-API standard to be also working with the OpenStudyBuilder.
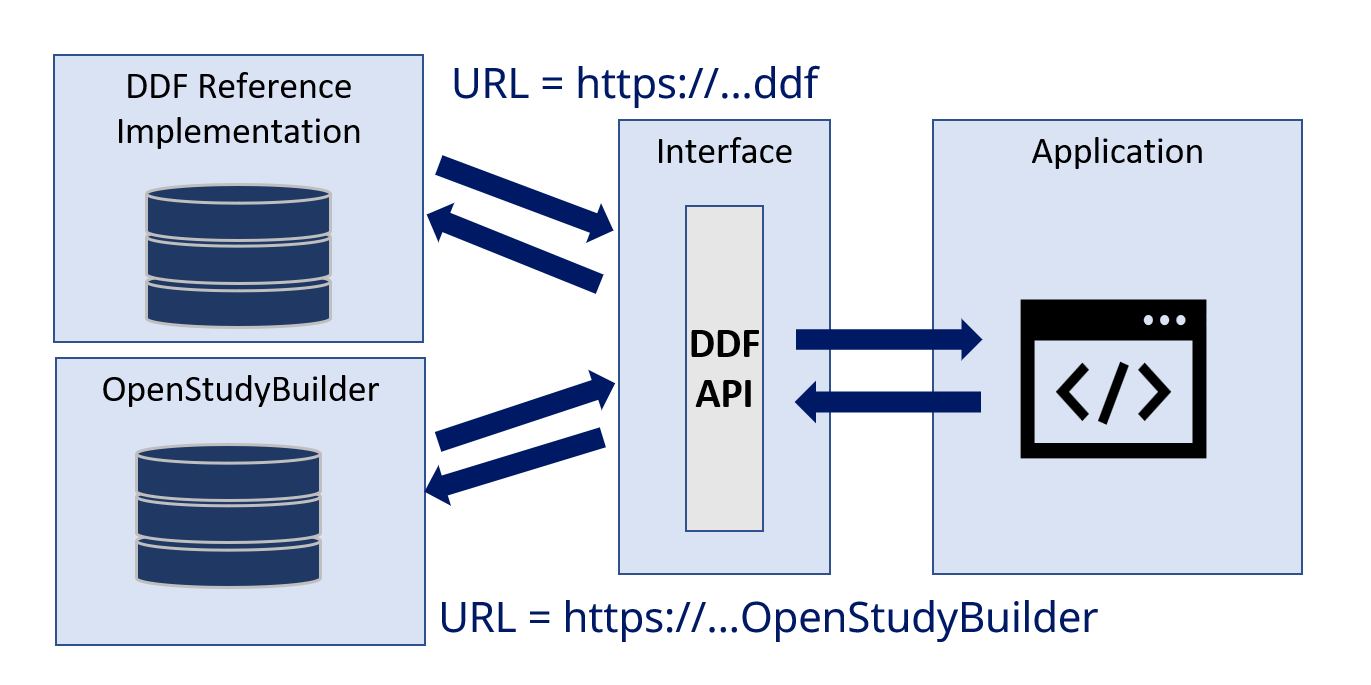
Figure 3: TransCelerate DDF API - Example
The potential for an Electronic Data Capture (EDC) tool to support the DDF standards is significant. By connecting just the different solutions, for example by specifying the URL in a configuration file, tools would not need any further integrations when all provide the same information. Currently the capabilities of the DDF API might not be as powerful as required. The native OpenStudyBuilder API provides many additional information which could be consumed. Nevertheless, the USDM standard promises a future where this endpoint will progressively encompass a broader spectrum of functionalities enabling a standard exchange.
API and Execution¶
OpenAPI and Swagger¶
For the API development and usage, there are excellent standards and tools available. The OpenAPI is a very common format for API specifications. This specification, which is available in the json format, can be important into many API tools - for example into Postman, a commonly used API interaction tool. Additionally, there is the Swagger documentation which also allows executing API calls easily.
In the OpenStudyBuilder you can download the OpenAPI either from the repository directly, or you can click the link in the Swagger documentation top right. This you can then load it into Postman to "Create a new collection". The Swagger documentation is an available component within the OpenStudyBuilder package - in the sandbox environment you can access this simply through a URL. In the other environments this is also available, for example by using a docker environment the default URL is http://localhost:5005/api/docs.

Figure 4: Download OpenAPI.json from Swagger documentation
Figure 5: Importing OpenAPI.json into Postman
There are different operations you can do with an API. The following standard operations are typically used for tasks:
| Operation | Description |
|---|---|
| GET | Retrieve data |
| PUT | Updates data |
| POST | Sends data for processing |
| DELETE | Removes data |
| PATCH | Updates data |
Swagger API Documentation¶
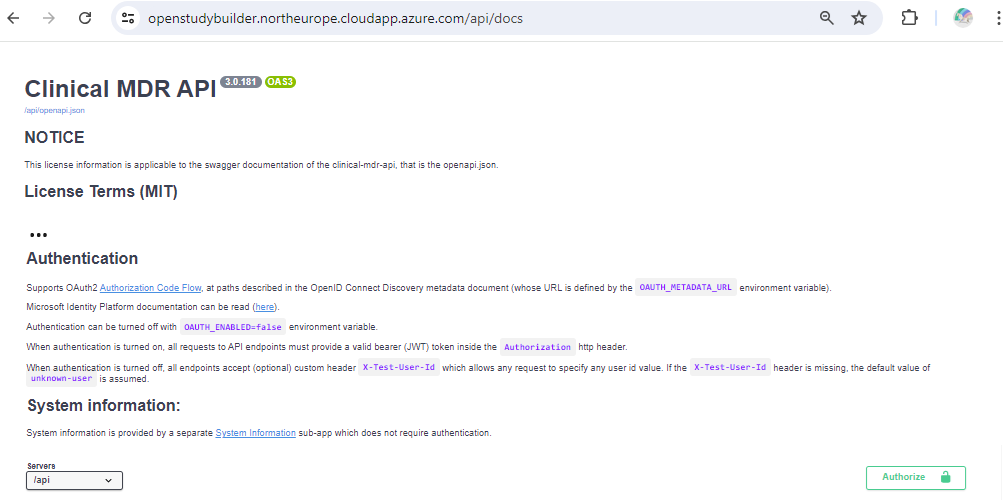
Figure 6: Swagger API documentation (top section)
The top section contains some general information including license information. Then there is an authentication section. If you have not changed the settings, the docker environment will have no authentication. But for the sandbox environment, you do need to authenticate. You can simply click "authorize" and then in the pop-up again "authorize" to allow the API calls to be executed later on. The specifications related to authentication flow depends on how the specific authentication has been set up in an environment. The specifications related to authentication flow depends on how the specific authentication has been set up in an environment.
You can see which endpoints are available. By being authorized you can additionally also execute these. There are many endpoints available which are grouped logically. Of course, it might be tricky to find the correct endpoint when you are not familiar with the used terminology used.
The ODM prefixes are for example connections related to ODM and CRF items. You can for example see CRF templates and download these in the ODM-XML format. The corresponding functionality in the app is located under "Library -> Concepts -> CRFs". The CT is all related to the controlled terminology management which is available in the application via "Library -> Code Lists".
Swagger API Execution¶
To execute an API call within this website is very easy. After authentication we can search for "/studies" to get to the related calls. The short description gives a good overview of what call will do.
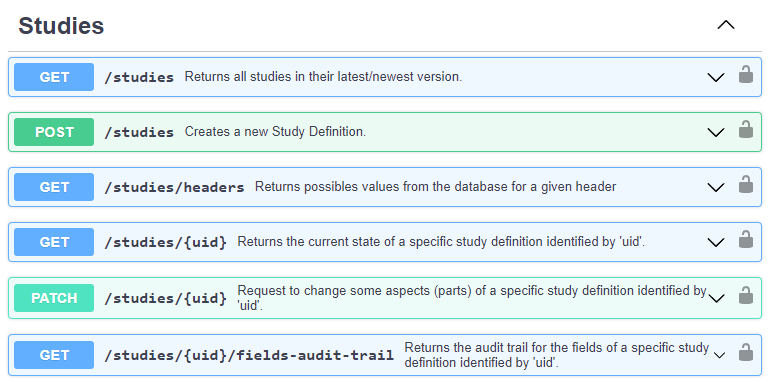
Figure 7: Swagger API documentation (Studies section)
When the "Get /studies" section is enlarged, many options are available. You might want to restrict the resulting data, filter by various conditions. Below you see the structure of return values which you might receive on success or failure. We can click on "Try it out" to be able to fill out the different parameters and execute that API command.
Note
Please note that the "filters" is pre-filled with an example {"*":{ "v": [""], "op": "co"}} - you need to remove this to get a result. This "filters" option is available and pre-filled in many calls, so please remember to remove those.
After executing this API call, you get a response.
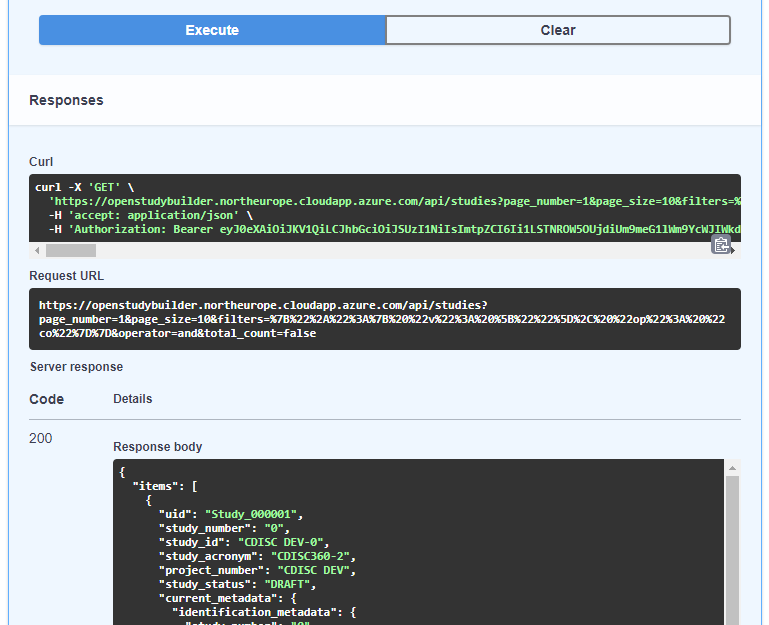
Figure 8: Swagger API Execution (/studies)
You receive a "Curl" statement, a "Request URL" and a "Response body". The "Response body" displays the data from your API call. The result is the "answer" to the API call question. It is available in JSON format, which is ideal to be processed further programmatically. The "CDISC DEV-0" study has for example the UID of "Study_000001". This is the unique identifier and is needed if you want to do follow up calls where you receive additional information or even change information.
The "Request URL" is nice to re-use in a browser or HTTP request. When using no authentication (for the docker environment for example), you can copy the URL into a browser and see the same result - just not formatted. If you want to use this HTTP request in any other tool like a web or R-Shiny application, you can simply use this URL. That's very generic and can be used from nearly any programming language. When you use authentication, e.g., like we have for the sandbox test environment, you need to take care for this and can work with that as well.
Most API tools support CURL requests. If you use a Linux system or a windows bash, you can even execute this CURL command to get the response. This CURL request also contains authentication (the bearer token in this case).
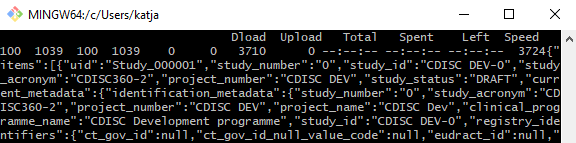
Figure 9: CURL command executed in Git Bash in Windows
Security Comments¶
In the OpenStudyBuilder project, authentication and authorization is being handled with OAuth 2.0 and OpenID Connect. Depending on the use-cases of OpenStudyBuilder and how you're connecting to the API, different authentication flows exist, such as client credentials flow, device code flow and authorization code flow. You should familiarize yourself with the authentication context that you're going to implement. For testing purposes, you can get an access token from the OpenStudyBuilder sandbox environment and using this for Bearer token authentication in other software solutions connecting to the API, such as SAS, R, or Postman. Such workflows should not be used for anything else than testing.
R example¶
As mentioned, this API can be called in any other kind of software. Let's use as example an R application connecting the sandbox environment with authentication. There are different packages available for http and CURL requests. The following example is using the httr package. As this is for test purposes, we are using a bearer token for authentication for simplicity.
# CURL example to get API results from OpenStudyBuilder
#
# Remark - you can get the current bearer token by executing by calling the API from the browser and copy the token
# goto - https://openstudybuilder.northeurope.cloudapp.azure.com/api/docs#/Studies/get_all_studies_get
# click "authorize" top right lock symbol, then "authorize"
# click "try it out"
# remove everything from the "filters" field
# click "execute"
# copy the bearer token from the CURL command (long string after "-H 'Authorization: Bearer ")
#
# setup for sandbox environment
api_url <- "https://openstudybuilder.northeurope.cloudapp.azure.com/api"
api_bearer <- "...." # get your specific one
library(httr)
response <- GET(paste(api_url,"studies", sep = "/"), add_headers(Authorization = paste("Bearer", api_bearer)))
studies <- jsonlite::fromJSON(rawToChar(response$content))
cat(studies[][["items"]][["uid"]], studies[][["items"]][["study_id"]])
response <- GET(paste(api_url,"ct/terms?codelist_name=Sex", sep = "/"), add_headers(Authorization = paste("Bearer", api_bearer)))
ct_sex <- jsonlite::fromJSON(rawToChar(response$content))
print(ct_sex[["items"]][["name"]][["sponsor_preferred_name"]])
We can simply get the resulting JSON file from a GET call and parse this into an R data frame. The first example ready in all studies which are available using the "/study" endpoint. Currently there is just one study available.
We can use also any other available endpoint. The second example shows how the "Sex" controlled terminology is downloaded.
Output:
> cat(studies[][["items"]][["uid"]], studies[][["items"]][["study_id"]])
Study_000001 CDISC DEV-0>
>
> print(ct_sex[["items"]][["name"]][["sponsor_preferred_name"]])
[1] "Female" "Intersex" "Male" "Unknown"
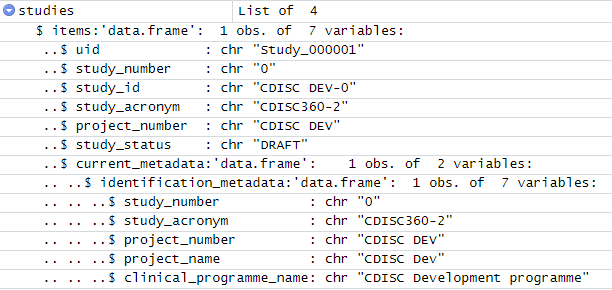
Figure 10: R data frame from API studies object
Note
When using a local OpenStudyBuilder instance without authentication, the authentication headers can be omitted to get the same result.
response <- GET(paste("http://localhost:5005/api","studies", sep = "/"))
studies <- jsonlite::fromJSON(rawToChar(response$content))
cat(studies[][["items"]][["uid"]], studies[][["items"]][["study_id"]])
SAS example¶
SAS is still the most common used programming language for clinical study evaluations. SAS provides the opportunity to perform API calls and process the response further. The following example is using a bearer authentication for the "/studies" endpoint. The API is calles through an HTTP request using PROC HTTP. The final result is a JSON file which can be transformed into a SAS library through the JSON library engine.
OPTIONS QUOTELENMAX;
/* define the bearer token and API endpoint variable */
%let bearer_token = eyJ0eXAiOi....; /* enter your token here */
%let api_endpoint = https://openstudybuilder.northeurope.cloudapp.azure.com/api/studies;
/* make the API call */
FILENAME response temp;
PROC HTTP URL="&api_endpoint" METHOD="GET" OUT=response;
debug level = 1;
HEADERS
"Authorization" = "Bearer &bearer_token"
"accept" = "application/json";
RUN;
/* Read in the JSON into a library */
LIBNAME response JSON;
The "ALLDATA" dataset in the assigned library containing the full content of the response.
Figure 11: ALLDATA dataset containing response
The first level information for the studies are contained in the "ITEMS" object, which can be seen by opening up the corresponding "ITEMS" dataset. At this timepoint there are three studies available in the OpenStudyBuilder sandbox environment.

Figure 12: ITEMS dataset containing response information for ITEMS
Note
When using a local OpenStudyBuilder instance without authentication, the authentication headers can be omitted to get the same result. This will only work when SAS is also running locally. A server version cannot access a local application.
DDF-API Overview¶
The TransCelerate Digital Data Flow (DDF) initiative is designed to pave the way for a future where study start-up processes are fully automated and dynamic. A key component of achieving this vision is the development of standardized APIs and the new Unified Study Definitions Model (USDM) that facilitate seamless integrations across systems.
DDF API Endpoint: The OpenStudyBuilder release 0.16.1 provides a DDF API Endpoint and visualization within the user interface. Studies can be exported in the USDM format in version 3.11. We are planning to export in USDM 4.0 by the end of 2025.
Swagger API Application: To interact with the API and download studies in the USDM format, users can utilize the Swagger API application. This tool is available for both sandbox and local environments:
- Sandbox Environment: https://openstudybuilder.northeurope.cloudapp.azure.com/api/docs
- Local Environment: http://localhost:5005/api/docs
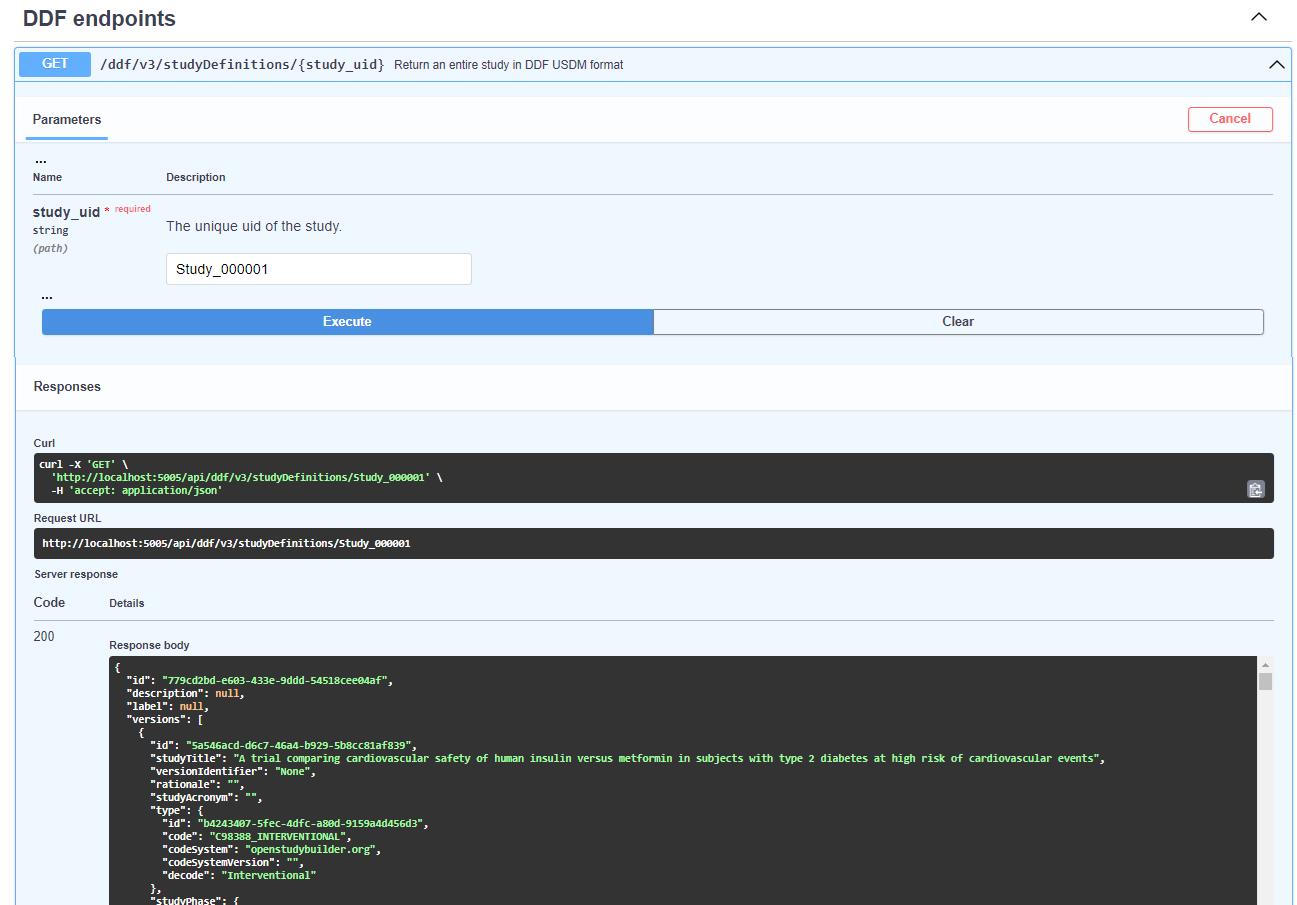
At the Swagger interface, navigate to the "DDF endpoints" section located at the bottom of the page.
How to Use
- Try It Out: Select the "try it out" option available in the DDF endpoints section.
- Enter Study UID: Input the
study_uidfor the study you wish to download. For demonstration purposes, you can use the example study UIDStudy_000001. - Execution and Output: Due to the comprehensive data collection process across the graph database, the execution time for this endpoint may be longer than others. Please allow a few seconds for the output to be generated and displayed.
Postman Integration¶
Postman is an essential tool for API testing and development, offering a streamlined way to integrate and interact with APIs like the one from the OpenStudyBuilder solution.
Importing the API Collection
You can import the entire API collection into Postman using a URL obtained from the Swagger documentation.
To begin, navigate to Postman and utilize the "Import" feature. Here, you can input the URL, such as https://openstudybuilder.northeurope.cloudapp.azure.com/api/openapi.json for accessing the sandbox environment, to import it as a new Postman Collection.
For those working with an unauthenticated API version, you can dive straight into testing. However, if authentication is required, it's crucial to manage access effectively. A common approach involves using a "Bearer Token" for authentication, which can be acquired either directly through the application or via the Swagger interface, ensuring secure and efficient access to API functionalities (see below).
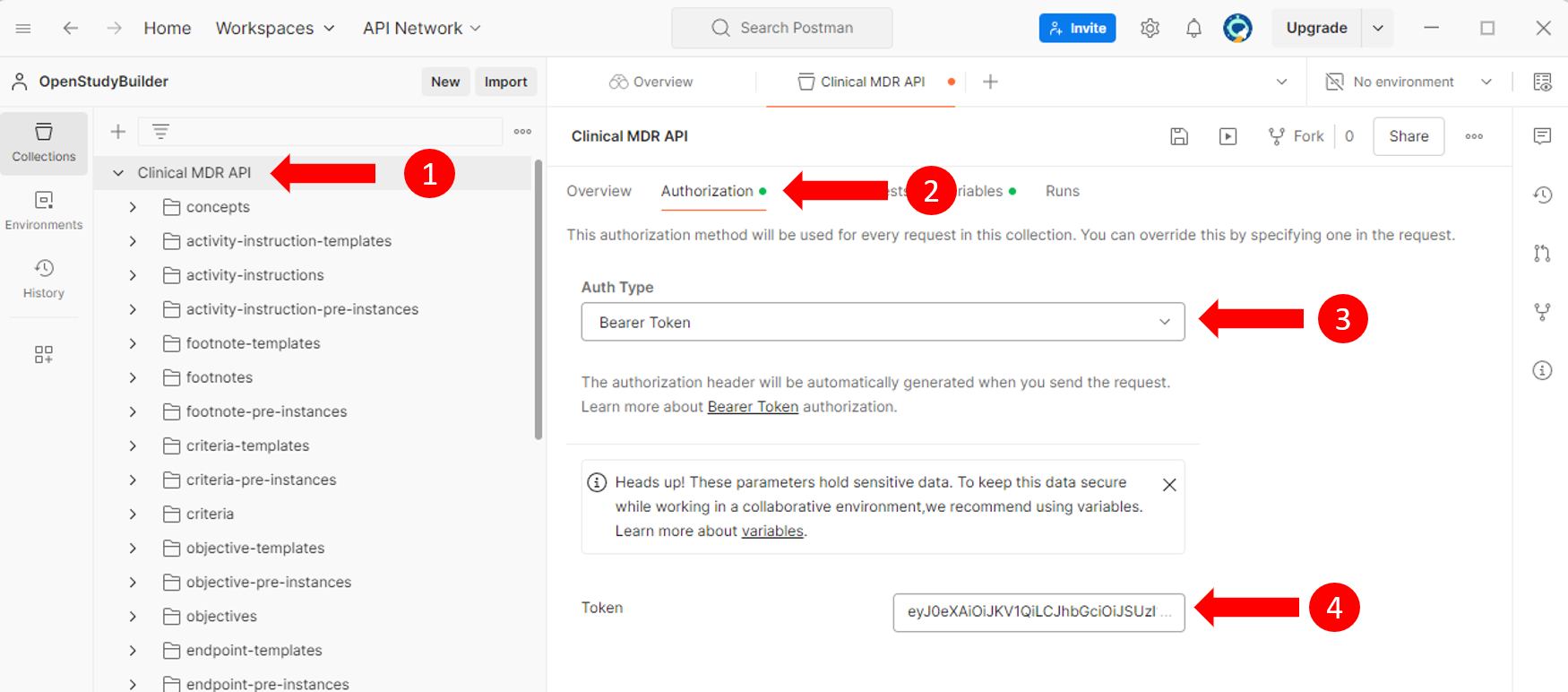
Setting Up Authentication
If the API requires authentication, a Bearer Token authentication setup could be used.
- Select the entire collection to apply settings globally (1).
- Navigate to the "Authorization" tab (2), select "Bearer Token" as the type (3), and enter your token (4).
Configuring the API Endpoint
Next, the concrete API endpoint needs to be set. This can be done by selecting the complete collection (1), selecting "Variables" (2) and enter the corresponding baseUrl (3) like "https://openstudybuilder.northeurope.cloudapp.azure.com/api".
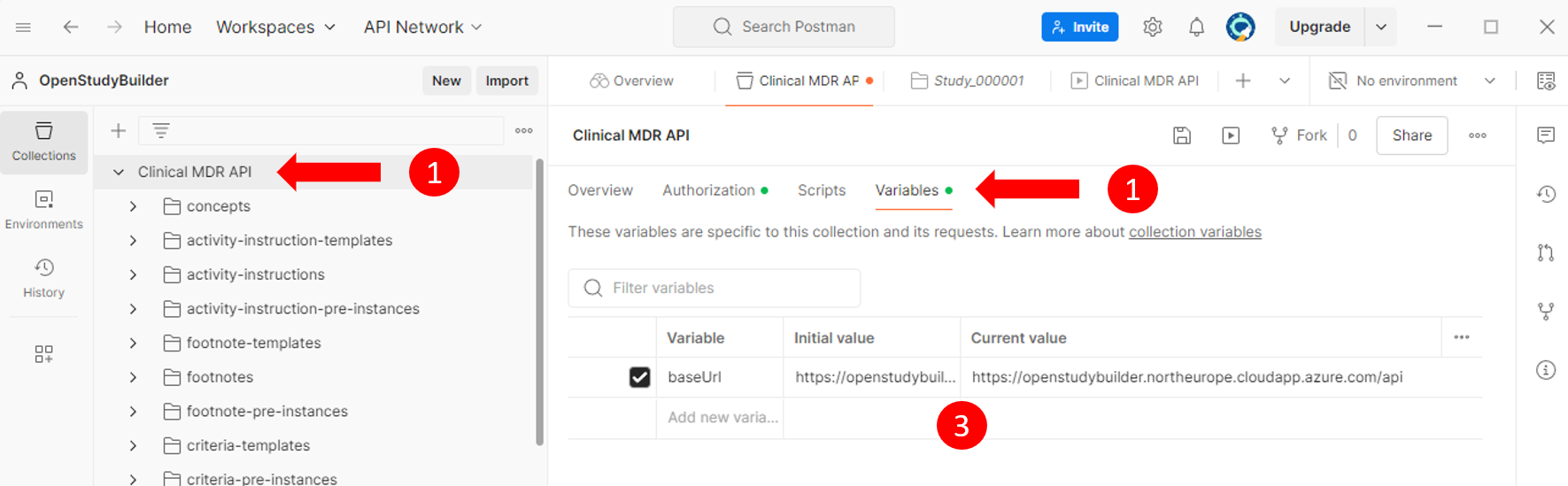
Ensure that all changes are saved to preserve your setup.
Making API Requests
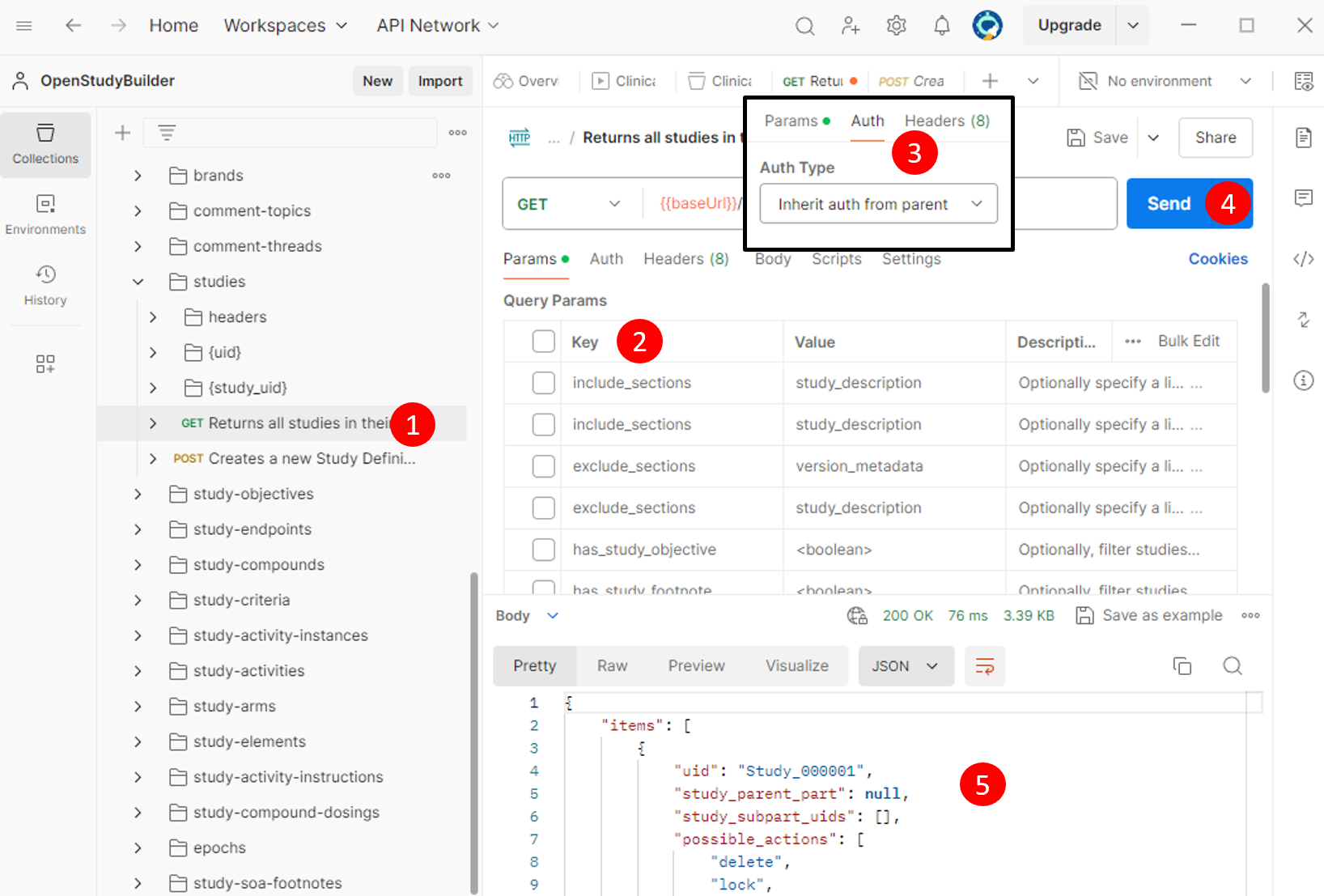
Finally, you can perform an API request.
- Select an Endpoint: Choose, for example, the "GET" endpoint for "studies" (1).
- Configure Parameters: Adjust parameters as necessary (all can be toggled by clicking "key") (2).
- Check authentication: Ensure the endpoint inherits the authentication settings (4).
- Send the Request: Execute the request (4).
- Review the Response: This will display either the requested data or an error message (e.g., token expiration or invalid parameters) (5).
Obtaining a Bearer Token¶
Securing a Bearer Token is a critical step for authenticating and interacting with the OpenStudyBuilder API. This token acts as a key, granting you access to the API's functionalities. Below are two methods to obtain your Bearer Token, either through the OpenStudyBuilder application or its Swagger documentation.
Via the OpenStudyBuilder Application
-
Access Developer Tools: Launch the OpenStudyBuilder application in your browser. Open the developer tools by pressing
F12in Chrome or the equivalent shortcut in your browser, and navigate to the "Network" tab. -
Perform an Action: Initiate an action within the application, such as selecting a study. This action triggers an API request, which is then logged in the Network tab.
-
Locate the Token: In the Network tab, look for an entry labeled "studies?..." or similar, indicative of the API request made. Clicking on this entry reveals the request details, including the endpoint URL (1) and the Bearer Token within the header information (2). This token can be copied and used for subsequent authentication requests.
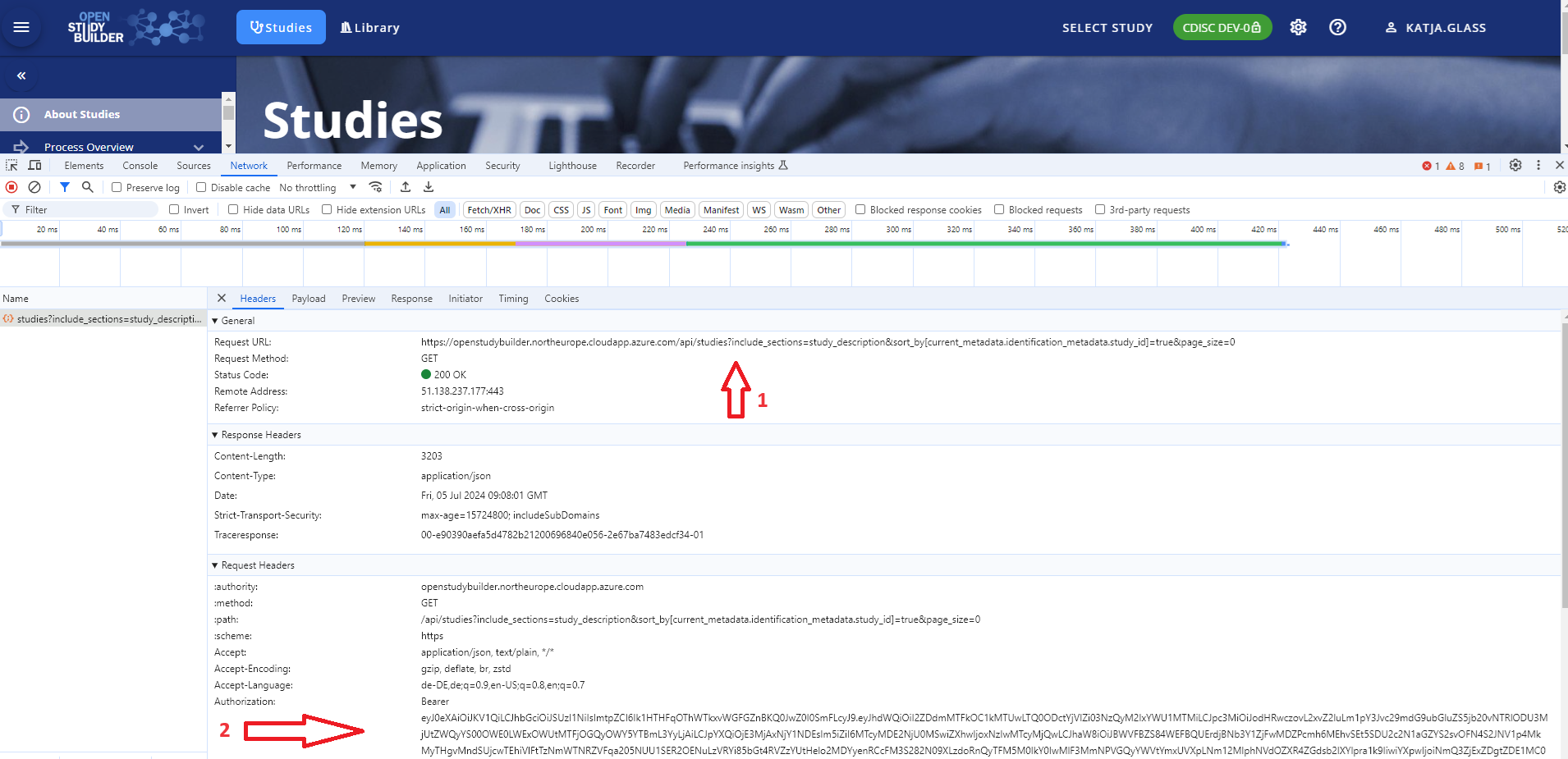 This image illustrates how to locate and copy the Bearer Token from the application's network traffic.
This image illustrates how to locate and copy the Bearer Token from the application's network traffic.
Note: The Bearer Token is temporary and will expire after a certain period. Ensure to refresh it periodically to maintain access.
Via the OpenStudyBuilder Swagger Documentation
-
Execute an Endpoint: Navigate to the OpenStudyBuilder Swagger documentation. Execute any API endpoint within the documentation interface.
-
Copy the Token: In the response section, a complete CURL request is displayed, which includes the Bearer Token. This token can be copied for use in authenticating your API requests.
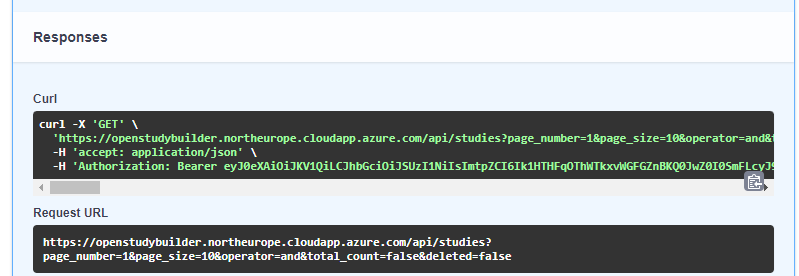 This image shows the CURL request in the Swagger documentation response, highlighting the Bearer Token.
This image shows the CURL request in the Swagger documentation response, highlighting the Bearer Token.
Both methods provide a straightforward way to obtain the Bearer Token, enabling secure and authenticated access to the OpenStudyBuilder API. Remember to handle this token with care, as it provides critical access permissions to the API and consider the token expiration.